You may often hear about “high throughput” or “scalability” in context of the requirements for a software. Usually, it’s intuitively understood like a software that should process a “lot of data”. In this article we uncover fundamental restrictions that limit system’s throughput and scalability.
The hidden bottleneck
Throughput of a system refers to a number of elements processed by the system over some time interval. For web applications the number of requests per second is usually used to measure system throughput. There are two simple conclusions we may make from that definition.
The first point is the less time is required to deal with a single input the more elements could be processed in some time interval, for example in a minute. To illustrate this, let’s imagine some machine that colors circles. The larger circle we put input into the machine the more time machine needs to color it. Quite obvious, that when we input large circles into the machine, its throughput is less than when we put the small ones.
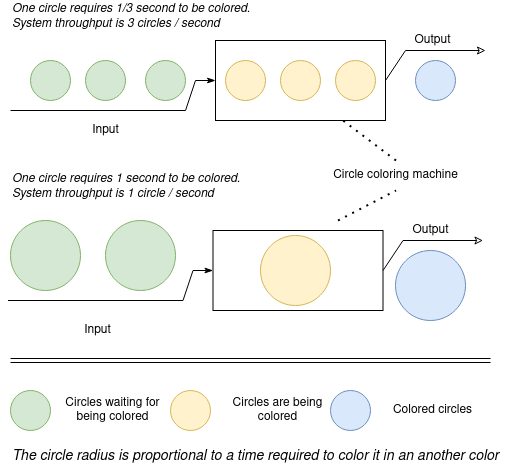
The second point is the more elements are processed in parallel the higher system throughput is. Quite obvious that if we color circles with two identical machines, the overall system’s throughput is higher than when there’s a single machine.
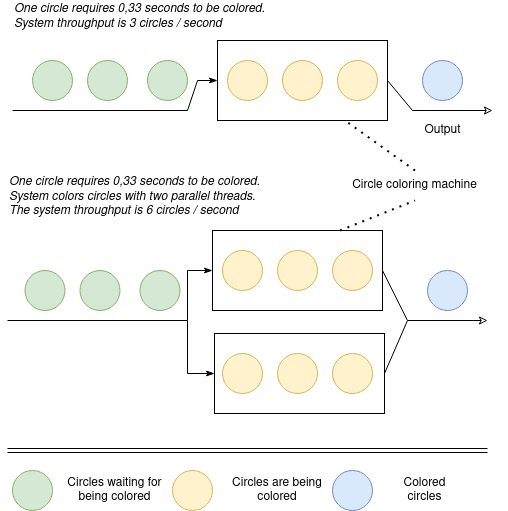
This beautiful picture on top demonstrate an ideal system in an ideal world that process completely uncoupled records. In practice, most of the time our informational records are interconnected and should stay consistent. The next picture illustrates how this affects system throughput. Even if the system has an available processing capacity it can’t fully utilize it due to element processing order limitations. Such limitations come from the need to preserve data consistency.
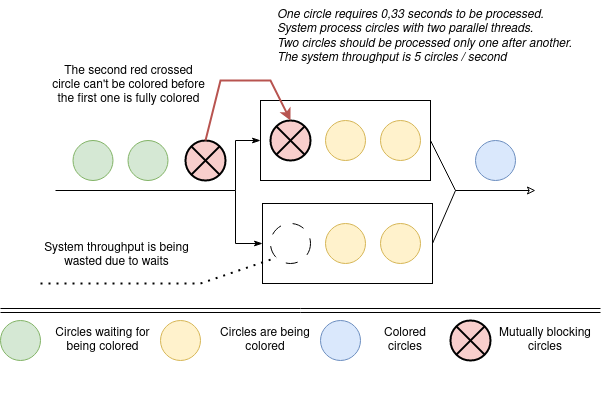
You may find such examples everywhere in the real world software. Imagine you’ve deposited $10 to your virtual bank card to pay for your favorite SaaS. Something went wrong and payment processing provider tried to perform 2 simultaneous withdrawals for $10. If your bank processes them in parallel, your balance become -$10. But, most probably the bank’s software will intentionally process these 2 transactions sequentially and decline the second one to prevent your card balance go below zero.
The similar thing happens in relational databases. By default, RDMS rearranges concurrent data updates in order to ensure data consistency. Usually, this complexity is hidden behind SQL interface, and you don’t think about it. However, sometimes the RDMS throughput degrades while slow query log is empty. In this case you have to learn more about internals of your RDMS engine and try to modify your queries to remove synchronization bottlenecks. Usually, this happens if reads to write ratio is one or less. In other words, the data is being modified more frequently than is being read.
Imagine you work with a message broker software, like RabbitMQ. You want to have at most once message delivery semantic.
You can’t retry message delivery, until the message processing acknowledgment timeout ends.
Once again, in case of the fault, you have to wait for 10 minutes or even more just to ensure that you don’t process the same message twice.
The long story short is that we face parallel execution’s synchronization bottlenecks all the time, still a middleware we use do it job quite well. It hides this problem from us as technology end users. Isn’t it the real power of a good abstraction?
Scalability
Another important thing about parallel processing is that a coordination of multiple worker (processes or threads) requires additional resources. The more surprising thing is that the more workers (CPUs or even servers) you allocate do deal with some job, the more resources you have to spent to make them work together and keep the results of the work consistent. Scalability is another concept you may hear often. It refers to a system’s ability to handle an increased amount of input data (or number of incoming requests) with a reasonable increase of consumed resources and without violation of other significant requirements, like data consistency or low response time.
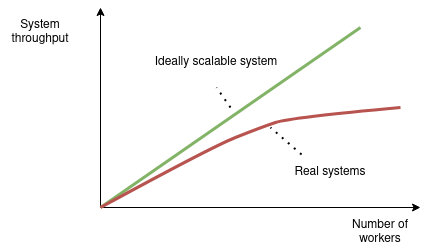
So, in very simple words, you’re software is scalable when it can process 1000 of requests per second with 1 server and 10 000 requests per seconds with 10 servers. The main restriction we see here is the number of servers we are able to allocate. Here’s another example of a system scalability requirement. If your system sorts of a collection of 1000 elements in less than 1 second it’s scalable, if it also can sort a collection of 100 000 elements in less then 1 second. In this case we’re mainly restricted by the time complexity of the sort operation. Probably, Buble Sort is not a good choice for sort algorithm in this case! Always check what the scalability means in each specific case and what restrictions you actually have!
How much computing power you have to allocate to preserve your data consistent in parallel computations? Well, it depends on what you do(the nature of the task) and how you do this (what is the system design). Let’s consider a very simple example of a integer counter increment performed by two threads. Very rough, we may reduce this simple program to following operations:
- Acquire mutex, about 17 nano seconds
- Get the variable from the main memory and move it to a CPU register, about 100 nano seconds
- Do integer increment, about 0.5 nano seconds
- Write variable back from the CPU register to the main memory, about 100 nano seconds
- Release mutex, about 17 nano seconds
The data on operations’ latencies is taken from Latency numbers every programmer should know. The time of the integer increment operation is considered to be equal to a length of one CPU cycle that depends on the CPU clock speed. In the example clock speed is 2GHz.
So, what’s interesting in this case? We spend approximately 200ns in a worst case to do an integer increment (for sure less, if CPU caches are used) and 34ns (17ns + 17ns, ~15% of time) to preserve data consistency. Another interesting thing, while the first thread do an integer increment, the second thread just wait for 200ns until the first thread release the mutex. So, the single counter variable is a system bottleneck. In fact, all updates are sequential still, not parallel.
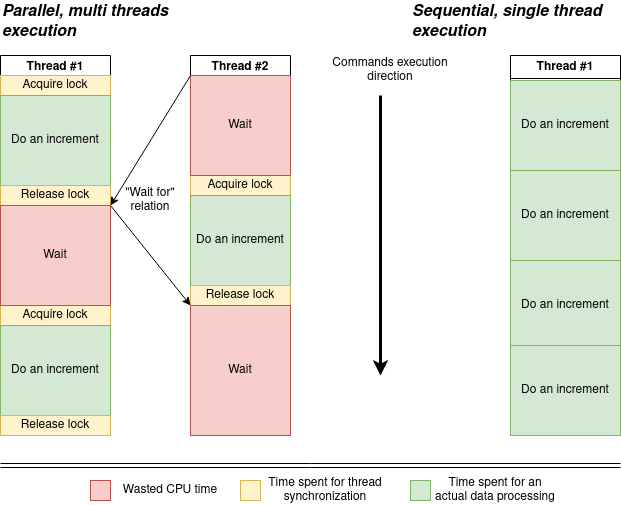 The allocated resources amount is two time more (200%). But as we spent 15% of time to order variable update instructions and all updates are in fact sequential, actual system throughput is only 85% from the single threaded version.
The allocated resources amount is two time more (200%). But as we spent 15% of time to order variable update instructions and all updates are in fact sequential, actual system throughput is only 85% from the single threaded version.
For sure, in real systems usually we introduce parallel execution when there’s something that we can actually do in parallel. For example, imagine a web application that serves HTTP requests and count them. In this case, the overall system throughput increases with the number of threads, because there’s something usefull that we can really do in parallel. For example update independent records in database. Still, as previous example shows, there are some pieces of work that we still have to do sequentially. As a result:
- We have to spend some resources to put our operations in specific order
- Sometimes we have just to wait, because there’s no work we can do without violating state consistency. This doesn’t allow to scale system’s throughput linearly.
Are there any ways to make a system from an increment counter example more scalable? It depends on why do we do this integer increments. Let’s imagine that we count a number of requests processed by our web server per minute. Probably, it’s enough to receive a consistent value of all processed requests only once in a minute. Let’s try another approach:
- Each thread has it own independent variable to count requests
- We do synchronization once in a minute, when we calculate sum of all independent counters.
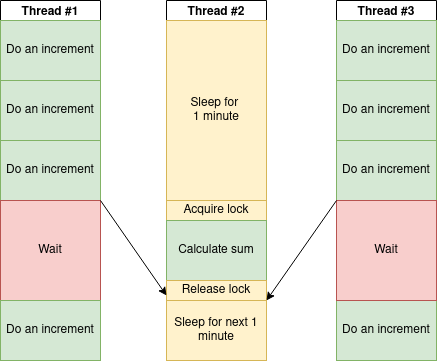
We receive correct data once in a minute while the time we spent for thread synchronizations is significantly lower! This is called Eventual consistency.
It’s worth to mention as a separate case, that sometimes you really deal with independent data. In this case, your system scales ideally, and you shouldn’t worry about parallel execution synchronization at all. For example, imagine a web service that resizes users’ images. All requests service receive are fully independent. Everything changes, if that service is going to bill users for requests and limit free users with only 5 requests. In this case you have to count simultaneous requests from the same user in a consistent way.
Conclusions
We can’t fully remove synchronization costs in parallel processing if they come from the task’s nature. Still we’re free to try different strategies to minimize those costs. Sometimes we have to rethink initial system requirements to adapt better synchronization strategies. Both approaches we used in this article are implementations of the Pessimistic Locking strategy. However, there’s an Optimistic Lock approach, that usually allows to achieve better system throughput. The problem’s nature does not change do we try to add more threads to our software or more servers to our deployment, that’s why the same tactics could be used to tackle it. As a rule of thumb, system throughput more likely will be affected by:
- How fast you can process single element
- How many elements you can process in parallel
- How effectively you synchronize parallel execution
Notes and References
Slow query log is a standard mechanism to find and troubleshoot queries performance. The idea is very simple: log queries that have execution time more than a threshold.